
Excelじゃできない…大量データのデータクレンジングと名寄せ方法とは?

現代のビジネス環境では、データは企業の重要な資産となっています。
しかし、膨大なデータを扱う際には、データのクレンジングや名寄せといった作業が不可欠です。Excelでは対応しきれないこれらの作業を効率的に行うためには、どのような方法があるのでしょうか?
この記事では、大量データのクレンジングと名寄せの具体的な方法について詳しく解説します。
データクレンジングと名寄せの基礎
データクレンジングとは?
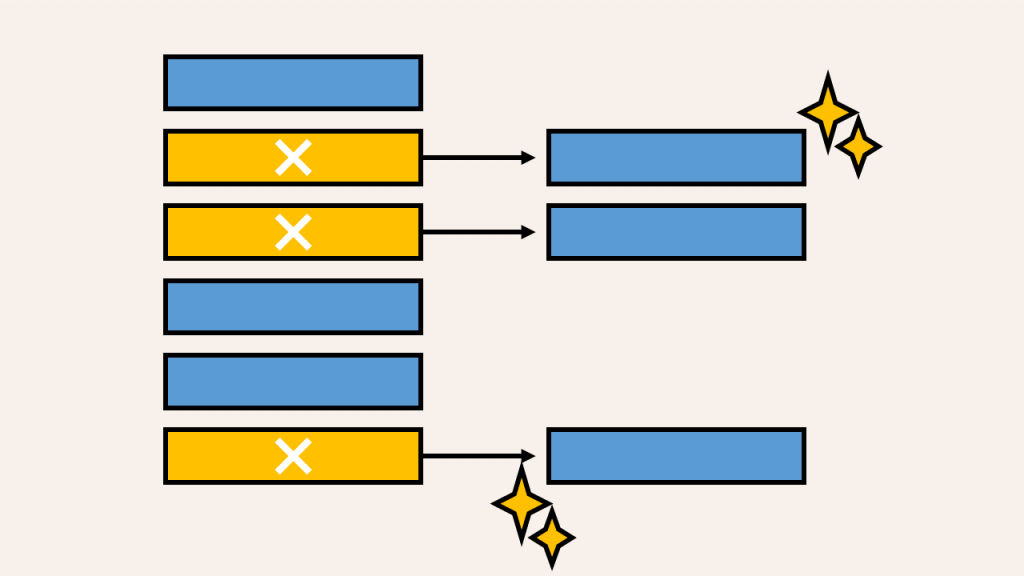
データクレンジングとは、不正確、不完全、または不適切なデータを特定し、修正、補完、もしくは削除するプロセスを指します。この作業により、企業の顧客データが一貫性を持ち、データ品質が向上します。
例えば、全角半角の不一致やハイフンの有無といった表記ゆれを解消することで、顧客情報が効率的かつ正確に活用できるようになります。特に住所データでは、番地や部屋番号、丁目の表記統一が欠かせないプロセスとなります。
名寄せとは?
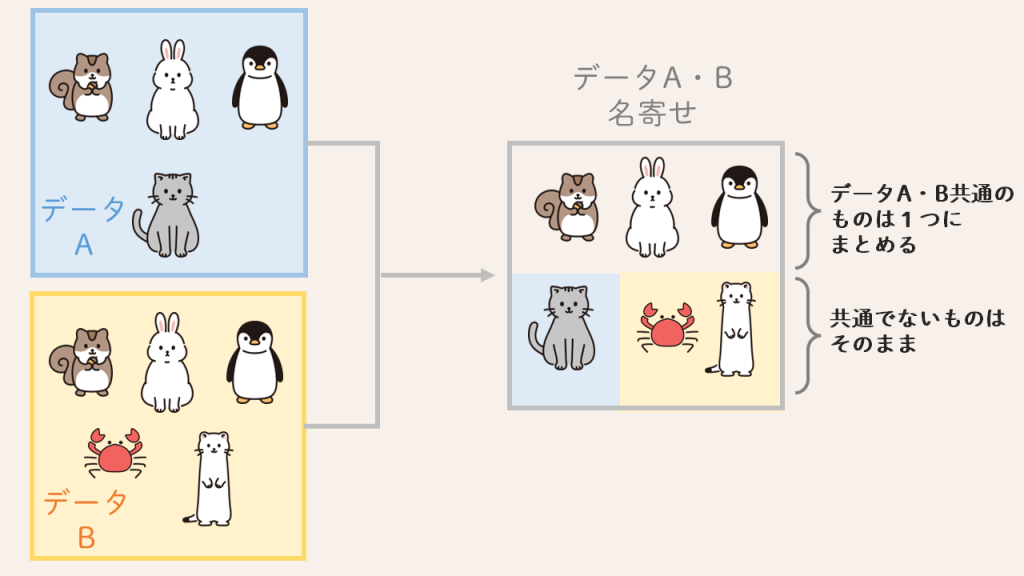
名寄せは、複数の異なるデータから同一の個人や企業を識別し、重複データを統合するプロセスを指します。
例えば、データAの「山田太郎」とデータBの「山田 太郎」が同じ人だと分かるようにする作業です。この名寄せによって、連絡ミスや送付物の重複送付を防ぐことができます。また、名寄せは顧客データの正確性を高め、営業活動やマーケティングの効率化につながります。
データクレンジングと名寄せの違いと、データ管理における役割
データクレンジングと名寄せは、実施目的に大きな違いがあります。
データクレンジングが主に不完全なデータの修正や表記ゆれの解消を目的とするのに対し、
名寄せは複数のデータを照合して重複データを識別し、同一データに纏めることを目的としています。
重複データは、顧客の信頼を損なう原因となり得ます。同じ封筒を複数回送付したり、異なる名称で顧客を登録して混乱を招いたりすることがその一例です。

これらを解決するためには、データクレンジングと名寄せのプロセスが必要不可欠です。具体的には、データ入力のルールを明確化し、重複の検出と統合をサポートするツールを活用することが効果的です。
データクレンジングによりデータが整理されることで、名寄せの精度も向上します。両方合わせて実施することにより、正確で一貫性のある情報管理につながります。
名寄せ作業の流れと効率化するためのポイント
手動処理と機械処理のメリット・デメリット
名寄せ作業を行う際に、手動処理と機械処理のどちらを選択するかを、データ特性や作業規模に応じて判断する必要があります。
手動処理のメリットは、より細かい情報や例外的なケースに対応できる点です。例えば、住所や名称における曖昧な部分の解釈が必要な場合や、特定顧客のデータを慎重に確認したい場合には手動が有効です。一方で、手作業では時間がかかり、多量のデータ処理が必要な場合には非効率となります。
一方、機械処理は大量のデータを短時間で処理できる点が最大のメリットです。データクレンジングツールを使用すれば、住所の番地や、英語表記ゆれの修正、異なるフォーマットで入力された情報の整備が容易になります。ただし、ツールの設定や機能によっては例外処理が困難な場合もあり、誤った統合や表記ミスが発生するリスクを伴います。
そのため、弊社では培った経験から最適な手動処理と機械処理を判断して組み合わせ、効率的かつ正確な大量データ統合を実現しています。

データクレンジングツールの導入で生産性向上を実現
データクレンジングツールは複数のデータファイルから重複データを特定・統合し情報の整理をします。きちんとしたプロセスを組むことで同一データを識別できるようになります。
例えば、ツールを活用することで「東京都新宿区西新宿1-1」と「東京都新宿区西新宿1丁目1番」が混在している場合でも同じデータとしてまとめることができます。
大量のデータを一括で精査し圧縮することで人的な労力を削減すると同時に、精度の高い情報を維持することが可能です。そのため、ツールを選ぶ時には、対象データに合った機能や、使いやすさを考慮する必要があります。
統一された基準とルールの設定が必要な理由
次に、名寄せ作業を適切に行うためには、まず統一された基準とルールが欠かせません。住所や名称に関する表記が拠点や担当者ごとで異なると、重複や誤情報が発生しやすくなります。
例えば、住民票や正式な住所の表記には「丁目」「番地」「号」が含まれますが、データ入力の際にこれらの情報が抜けたり、部屋番号が未記載の場合、配送や連絡の遅れにつながる恐れがあります。そのため事前のデータクレンジングで表記を統一しておきます。
また、顧客ごとに微妙に異なる名称のデータが複数記載されている場合、「どれが正確な情報か」を判断するのが難しくなります。そのため、住所や名称のルール(例: 全角と半角の統一)や判断方法のガイドラインを制定し、統一されたルールのもと適切な機械処理をすることが重要です。

顧客満足度を向上させた事例
大量データを統合し、顧客の業務効率化に貢献した弊社実施事例を紹介します。
あるキャンペーン事業ではデータクレンジングと名寄せを実施し、複数の住所や異なる表記で入力されたデータを統一しました。この取り組みで、重複送付の件数が激減し、住所不備による再配送コストを削減できたことはもちろん、顧客からの信頼を大きく向上させる結果を得ました。
(事例)キャンペーン事業A
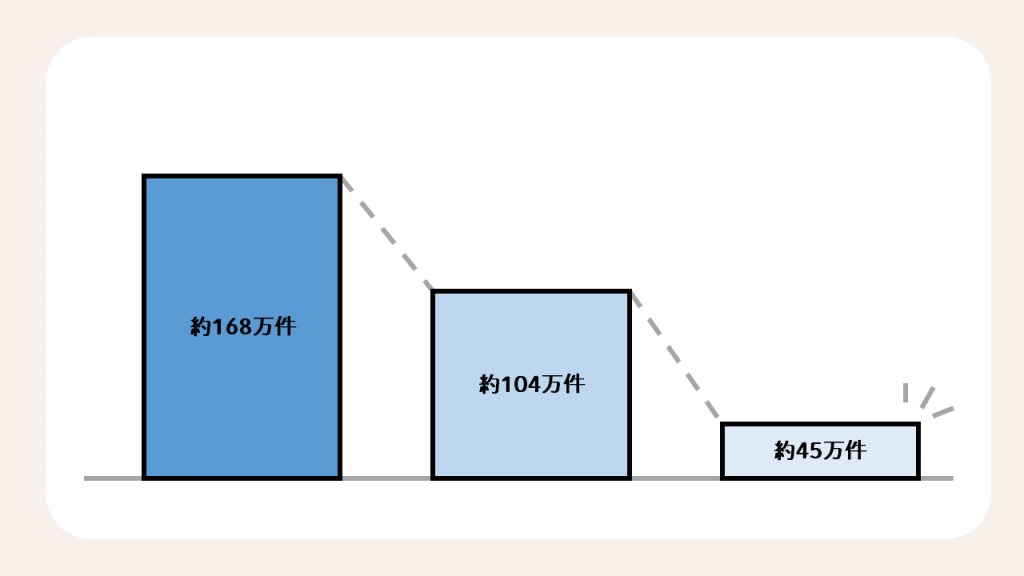
・データ総件数 :約168万件
・データクレンジング(機械処理)後の件数:約168万件 → 約104万件
・名寄せ(目視検査/手動処理)後の件数 :約104万件 → 約45万件
・名寄せ処理日数 :合計14営業日
精度の高いデータがもたらすビジネス価値
データクレンジングと名寄せのプロセスを経て住所や名称の統一を進めると、ビジネスにおいて大きな価値を生み出します。
例えば、データクレンジングで不正確な住所や名称を改め、番地や丁目などの表記ゆれを統一することで、顧客への配送遅延や連絡ミスを防ぐことが可能になります。
また、名寄せにより重複データを統一したデータは正確な顧客分析に繋がります。重複のないデータはマーケティング戦略の精度を高めるだけでなく、無駄なコストの削減にも貢献します。
特に企業間でのデータクレンジングや名寄せは、複数の拠点や部門で管理されたデータを一元化し、効率的なデータ運用を可能にします。
さらに、名寄せツールや専門機関によるデータ整備サービスを利用することで運用負荷を軽減し、効率的なデータ管理を実現することも可能です。
弊社では豊富な経験から確立した最適な手動処理と機械処理手法により、効率的に正確な大量データ統合サービスを実現しています。
大量データの整備でお困りの際はお気軽にご相談ください。
\資料ダウンロードはこちら!/
\費用感や必要な期間等、詳しくはこちらから!/